Monitoring GPU Usage per Engine or Application
GPUs, just like any other hardware, need to be sized properly. If there is unused capacity, money is being wasted. If, on the other hand, utilization is at maximum, the user experience is poor. Sizing requires information. In this case, about GPU usage, ideally per GPU engine and application. uberAgent delivers.
GPU Architecture
GPUs are comprised of thousands of cores that run the same instructions in parallel on multiple data. This GPU architecture was initially designed for 3D rendering but has been found to be useful for any kind of application where algorithms are highly parallelizable.
Combined, a GPU’s cores are often called the 3D engine. While 3D is typically the most important engine, GPUs also have specialized engines that add capabilities like video encoding or decoding. Without those, smartphones would never be able to record HD video or play it back in real-time.
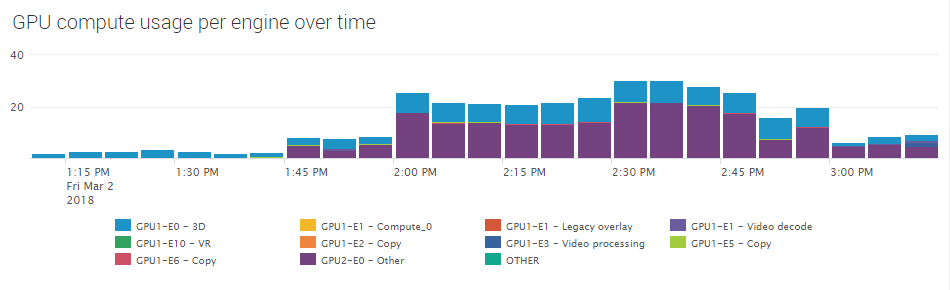
Monitoring GPU Usage per Engine
GPU monitoring presents some unique challenges. Different GPU models have different capabilities, which results in different types and numbers of engines.
uberAgent is prepared for that. It dynamically detects a GPU’s engines and determines each engine’s utilization individually. When displayed in a chart over time, this allows a viewer to grasp any engine’s resource usage immediately:
Monitoring GPU Usage per Application
A GPU’s resources are available for all processes that are running on a machine. Being able to discern which application generates what kind of load is crucial. In some cases, similar applications are very different with regards to efficiency and GPU resource footprint. This applies to browsers, for example. In other cases, applications you would expect to make good use of the GPU don’t.
By providing GPU utilization metrics per process, uberAgent helps IT understand and optimize GPUs for their application set.
Monitoring GPU Usage per Machine
In addition to the resource consumption per GPU engine and per application uberAgent also collects the GPU usage per machine. If a machine has more than one GPU, the numbers are collected individually per GPU. This is useful for gaining an understanding of the overall GPU utilization, both in terms of GPU compute and GPU memory resources.
About uberAgent
The uberAgent product family offers innovative digital employee experience monitoring and endpoint security analytics for Windows and macOS.
uberAgent UXM highlights include detailed information about boot and logon duration, application unresponsiveness detection, network reliability drill-downs, process startup duration, application usage metering, browser performance, web app metrics, and Citrix insights. All these varied aspects of system performance and reliability are smartly brought together in the Experience Score dashboard.
uberAgent ESA excels with a sophisticated Threat Detection Engine, endpoint security & compliance rating, the uAQL query language, detection of risky activity, DNS query monitoring, hash calculation, registry monitoring, and Authenticode signature verification. uberAgent ESA comes with Sysmon and Sigma rule converters, a graphical rule editor, and uses a simple yet powerful query language instead of XML.
About vast limits
vast limits GmbH is the company behind uberAgent, the innovative digital employee experience monitoring and endpoint security analytics product. vast limits’ customer list includes organizations from industries like finance, healthcare, professional services, and education, ranging from medium-sized businesses to global enterprises. vast limits’ network of qualified solution partners ensures best-in-class service and support anywhere in the world.


